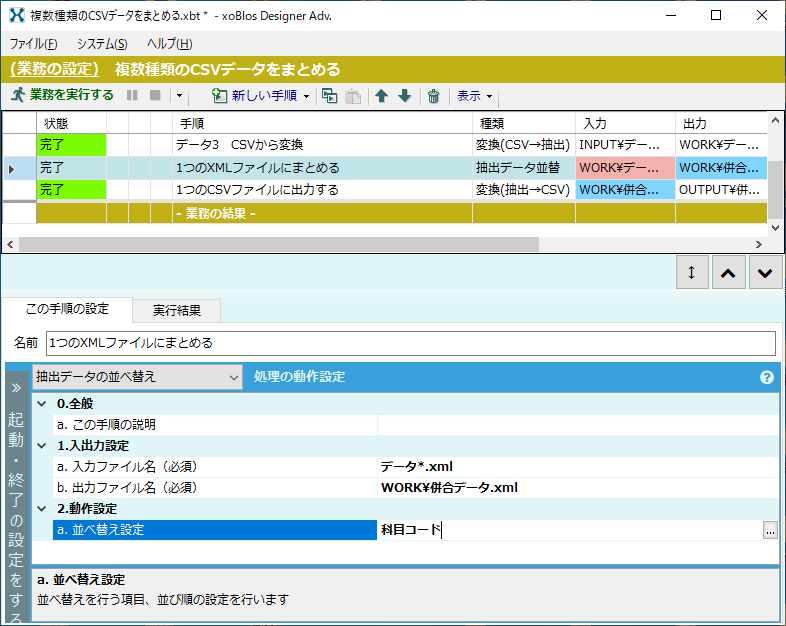
CSVデータなどから抽出したXMLデータで、項目順(項目名の出現位置)がばらばらな複数ファイルがあったとします。



この複数XMLファイルを「抽出データの並べ替え」手順で併合(マージ)してみます。

出力結果を見ると、ばらばらな項目順が統一して揃えられていることがわかります。

「抽出データの並べ替え」手順で「並べ替え設定」を行えば、指定したキー順にソート(並べ替え)もできます。

xoBlos コントローラーの corabo(Webアプリ)で、ファイルをアップロードする画面が出てきます。[ファイル選択] ボタンをクリックして、ファイルを開くダイアログで選択もできますが、ファイルのドラッグ&ドロップでも選択できるのでお試しください。



親プロセスから業務変数を子プロセスに渡す https://xoblos.hatenablog.jp/entry/2024/03/11/142529
上記の記事で解説した、業務変数を子プロセスに渡す手法は、子業務(子プロセス)を 繰り返し実行する要件にも適用でき、処理手順のコンパクト化に役立ちます。
【コンパクト化前の業務手順】

【コンパクト化後の業務手順】


親業務から [実行時に指定する業務の値] で、繰り返し基準ファイルから取得した項目変数の値 $(item:"代理店コード")、$(item:"代理店名") を子業務に渡し、子業務ではそれを「代理店コード」「代理店名」という業務変数で受けて使用しています。
下図は、一般的な真理値表(真偽表)のOR演算とAND演算に関して、Excelで表現してみた図です。

筆者が初めてコンピューター業務に触れたのは、八王子にある工場に出向して、工場の原価計算業務を大型汎用機(メインフレームコンピューター)で開発するチームで仕事をしたときです。かれこれ、40年前になります。
その若かりし当時、COBOLとかPL/Iといったプログラミング言語で苦闘していたときと、現在xoBlos(ゾブロス)業務を組み立てているときとで、この真理値表の域を出ていない事に気が付きました。
今回、真理値表に色を塗るにあたり、「偽」「FALSE」は桜色で表現してみました。
さまざまの こと思ひ出す 桜かな (芭蕉)
XMLからパラメータを取得して作業変数にセットする https://xoblos.hatenablog.jp/entry/2024/03/22/042555
上記の記事では、xoBlos Ver 1.8 から機能追加された、XMLファイルから作業変数に値をセットする方法を解説しました。今回の記事では、これも xoBlos Ver 1.8 から機能追加された、Excelシートから作業変数に値をセットする方法を解説します。





ポイントは、次のようにExcelシートのアドレスを [取得元アドレスの指定] に設定する点です。
[作業変数の名前] 年度
[対象シート] パラメータ
[取得元アドレスの指定] A2
[作業変数の名前] 半期
[対象シート] パラメータ
[取得元アドレスの指定] B2
[作業変数の名前] 四半期
[対象シート] パラメータ
[取得元アドレスの指定] C2

後続手順で、$(tmp:年度)、$(tmp:半期)、$(tmp:四半期) の形式で作業変数として使用できます。
作業変数を複数設定する
https://xoblos.hatenablog.jp/entry/2021/10/19/035041
CSV形式やExcelシートから値を作業変数にセットする
https://xoblos.hatenablog.jp/entry/2022/09/30/065249
上記の記事では、xoBlos Ver 1.7 までの作業変数の設定方法を解説しましたが、JSON形式を意識する設定が必要でした。
xoBlos Ver 1.8 からは、XML形式やExcelシートからもパラメータを取得して、作業変数にセットすることが可能となりましたが、今回はXMLからの設定方法を解説します。

CSVデータからの場合は 「変換(CSV→抽出データ)」 手順、Excelシートからの場合は、「Excel表から抽出」 手順で変換します。




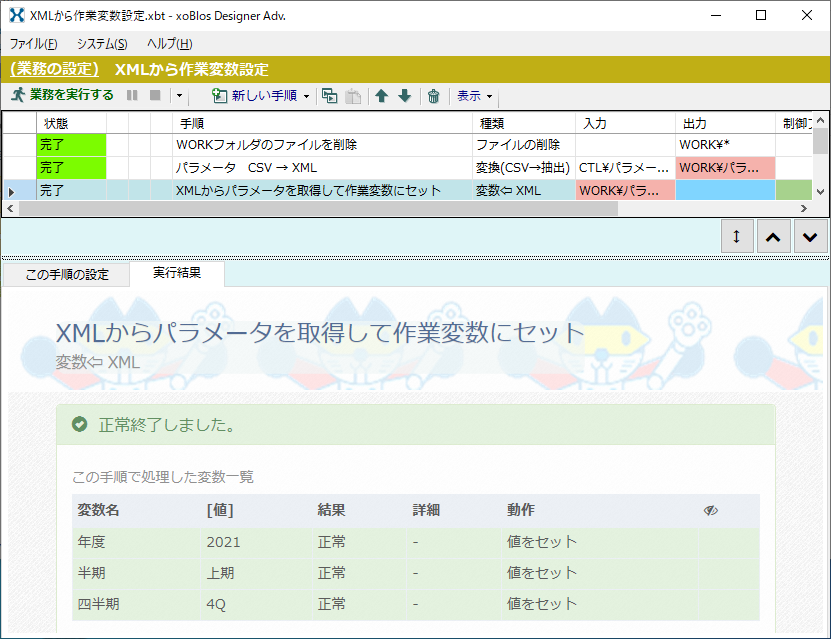
後続手順で、$(tmp:年度)、$(tmp:半期)、$(tmp:四半期) の形式で作業変数として使用できます。