取得したHTMLページをxoBlosで扱えるようにする (1) https://xoblos.hatenablog.jp/entry/2024/01/30/153210
上記の記事の続きです。
XMLの規格の中には、エンティティ参照(Entity reference)と呼ばれるエスケープ文字の規格があります。簡単に言うと、XMLデータとして記述するときに、& や < とは記述できず、& や < と記述する必要があるということです。
|
文字
|
置き換えテキスト
|
|---|---|
| & | & |
| < | < |
| > | > |
| " | " |
下図のような「変換(XML→抽出データ)」手順でHTMLファイルを変換しようとすると、文字(値)としての半角 &(アンパサンド)が含まれるとエラーとなります。& がエスケープ用の開始記号だからです。
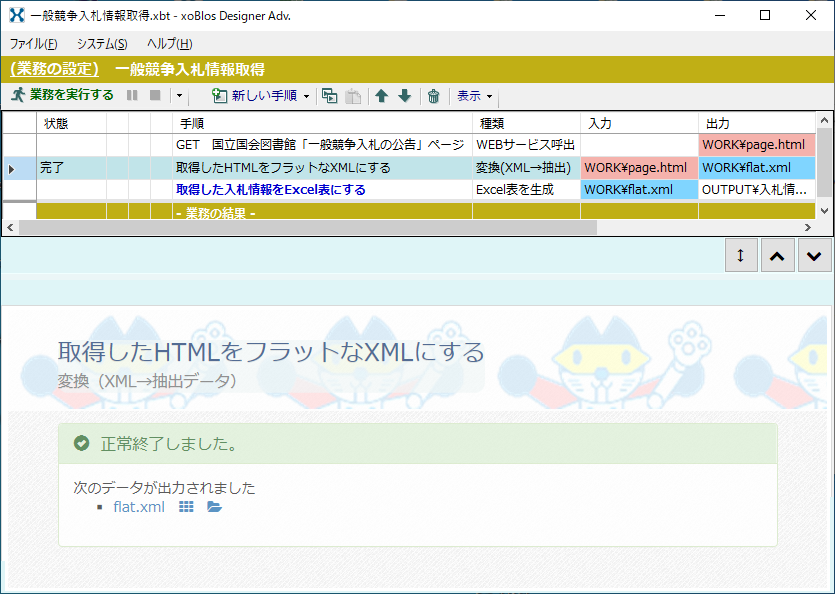
> と " は、「変換(XML→抽出データ)」手順ではエラーとしていません。< は、元々のHTMLにデータ(値)として < があると、ブラウザ表示などが破綻するため、単独で < はないものとの前提で動作します。
この半角 & の問題を解決するために、xoBlos Ver 1.8 から追加された、「作業変数へセット」「変数値の出力」手順のテキストファイル対応の機能が使えます。

取得したHTMLファイルを1行ずつ処理し、半角 & を別の文字列(空にして削除、全角&、エスケープ表記の & など)に変換します。手順の設定に関しては、下記の記事を参考にしてください。
CSVファイルのテキスト一括置換(解決編) https://xoblos.hatenablog.jp/entry/2024/01/29/040801
半角 & を全角 & に変換する設定が下図です。
